Abstract
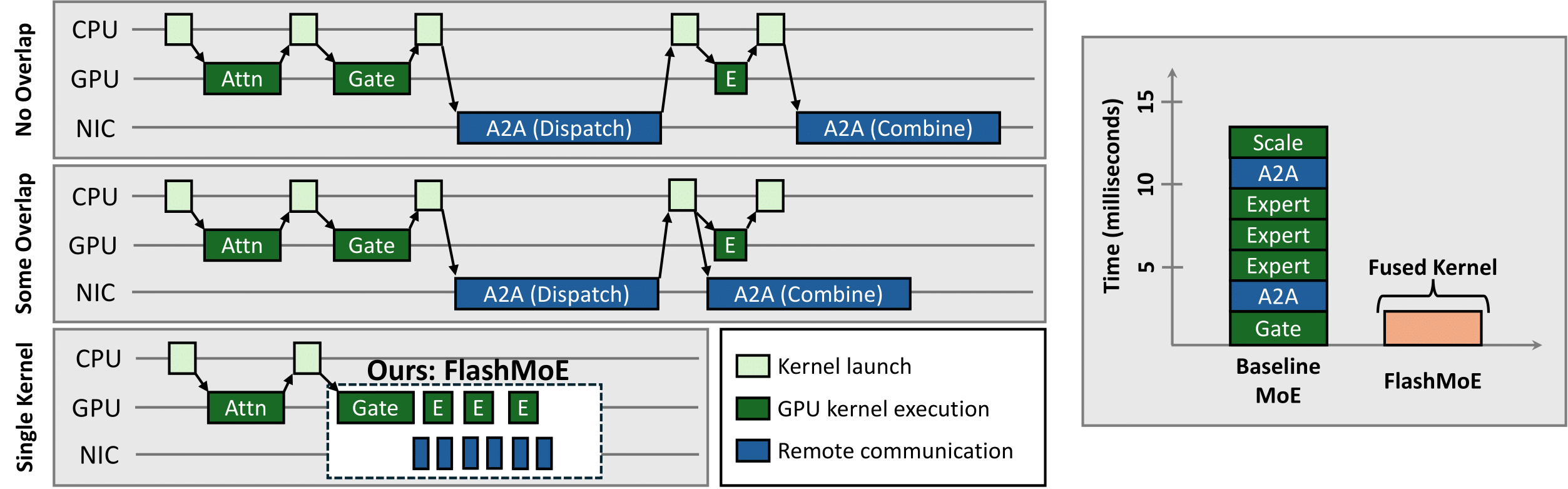
The computational sparsity of Mixture-of-Experts (MoE) models enables sub-linear growth in compute cost as model size increases, thus offering a scalable path to training massive neural networks. However, existing implementations suffer from low GPU utilization, significant latency overhead, and a fundamental inability to leverage task locality, primarily due to CPU-managed scheduling, host-initiated communication, and frequent kernel launches. To overcome these limitations, we develop FlashMoE, a fully GPU-resident MoE operator that fuses expert computation and inter-GPU communication into a single persistent GPU kernel. FlashMoE enables fine-grained pipelining of dispatch, compute, and combine phases, eliminating launch overheads and reducing idle gaps. Unlike existing work, FlashMoE obviates bulk-synchronous collectives for one-sided, device-initiated, inter-GPU (R)DMA transfers, thus unlocking payload efficiency, where we eliminate bloated or redundant network payloads in sparsely activated layers. When evaluated on an 8-H100 GPU node with MoE models having up to 128 experts and 16K token sequences, FlashMoE achieves up to 9× higher GPU utilization, 6× lower latency, 5.7× higher throughput, and 4× better overlap efficiency compared to state-of-the-art baselines—despite using FP32 while baselines use FP16. FlashMoE shows that principled GPU kernel–hardware co-design is key to unlocking the performance ceiling of large-scale distributed ML. We provide code at https://github.com/osayamenja/FlashMoE.
System Overview
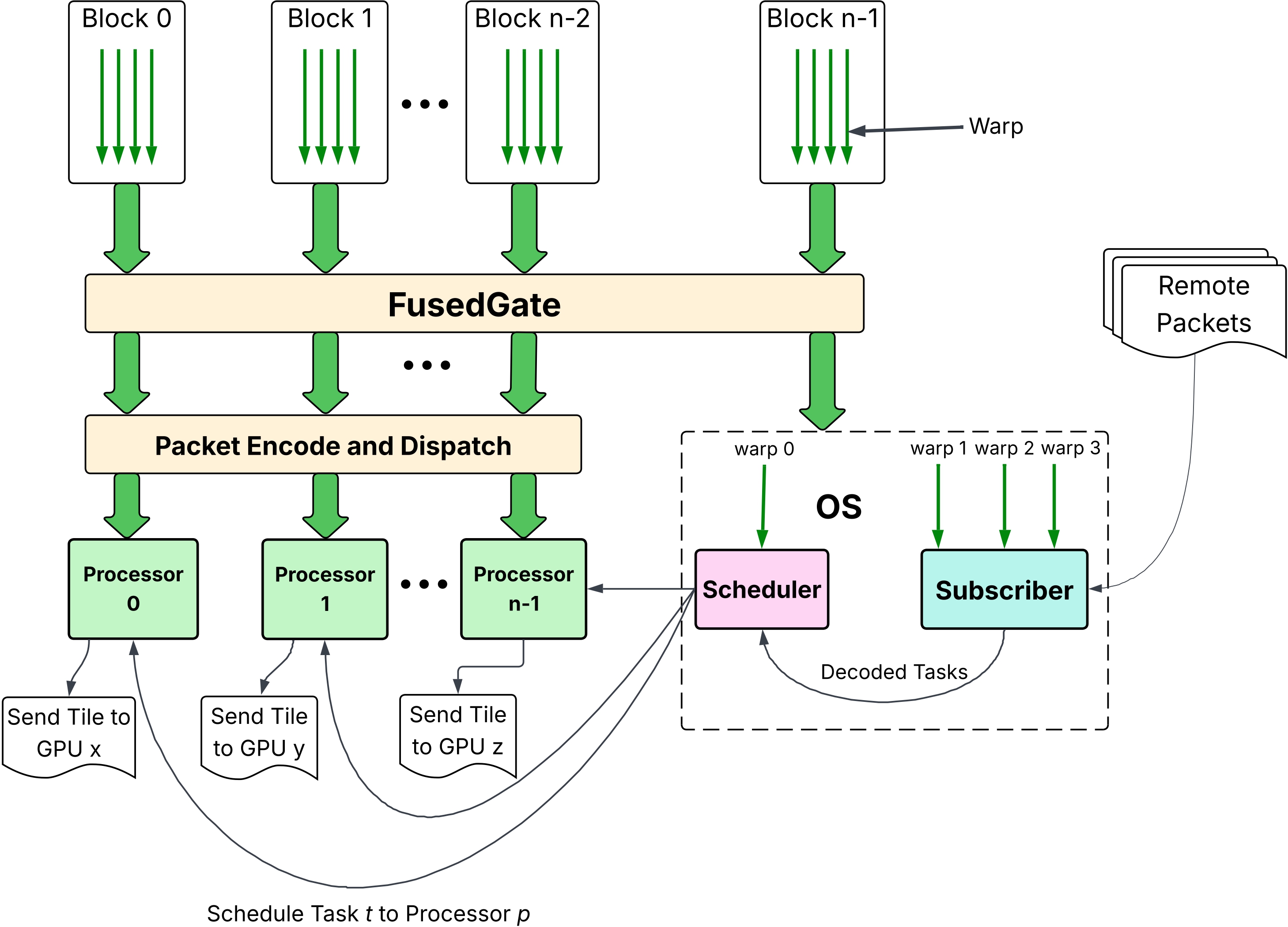
Fused kernel architecture.
Results
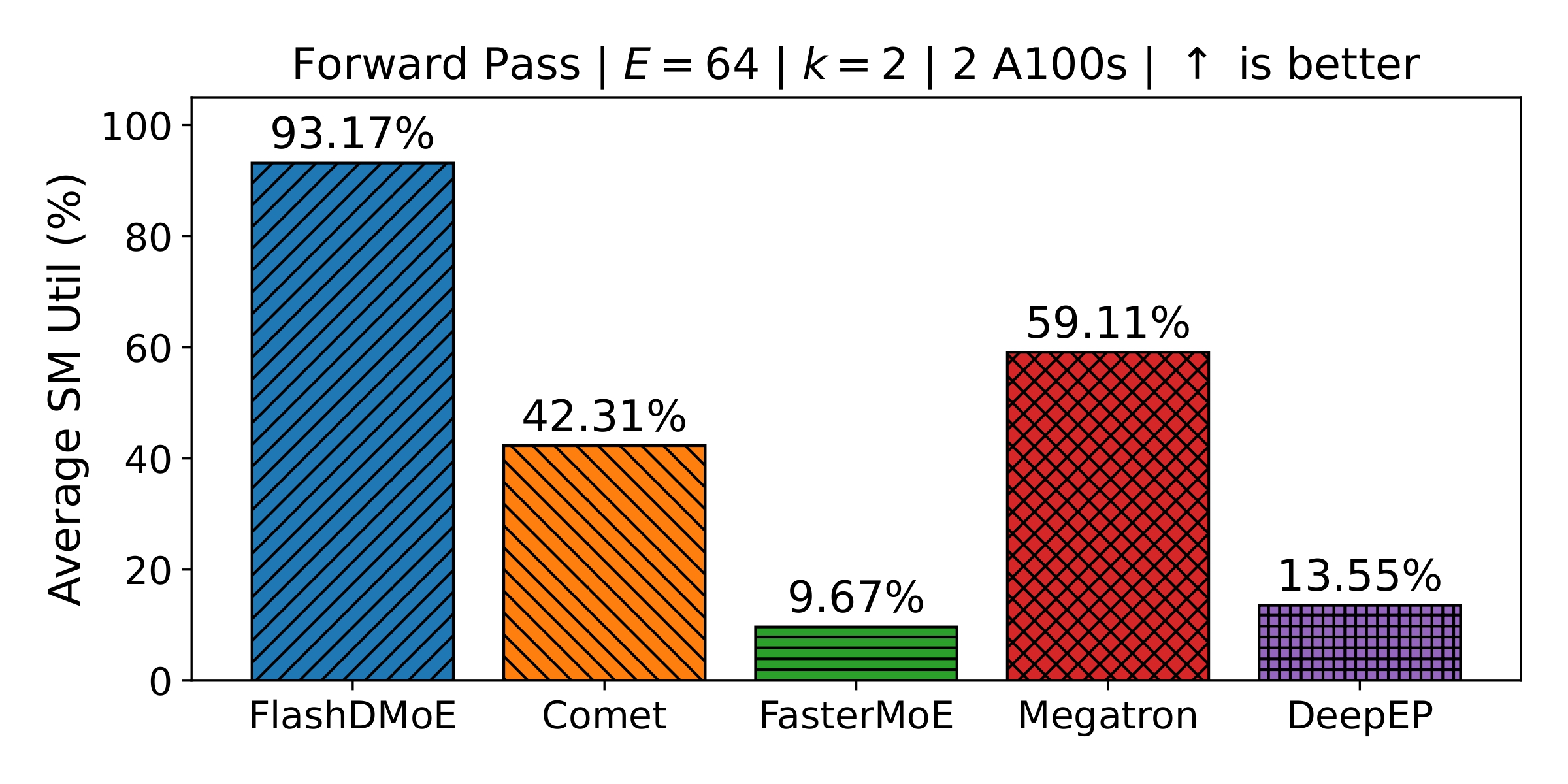
GPU SM Utilization
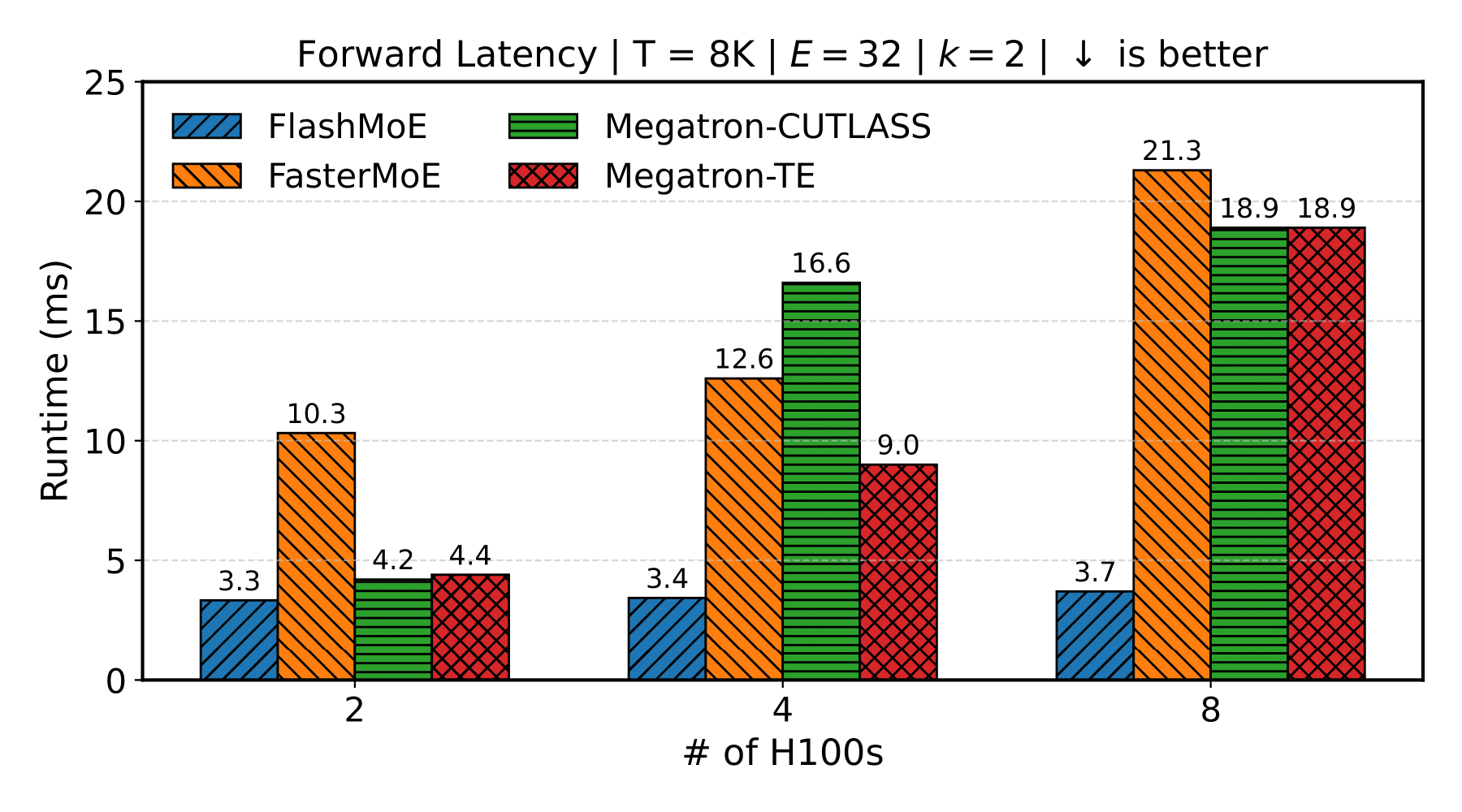
Scaling GPUs
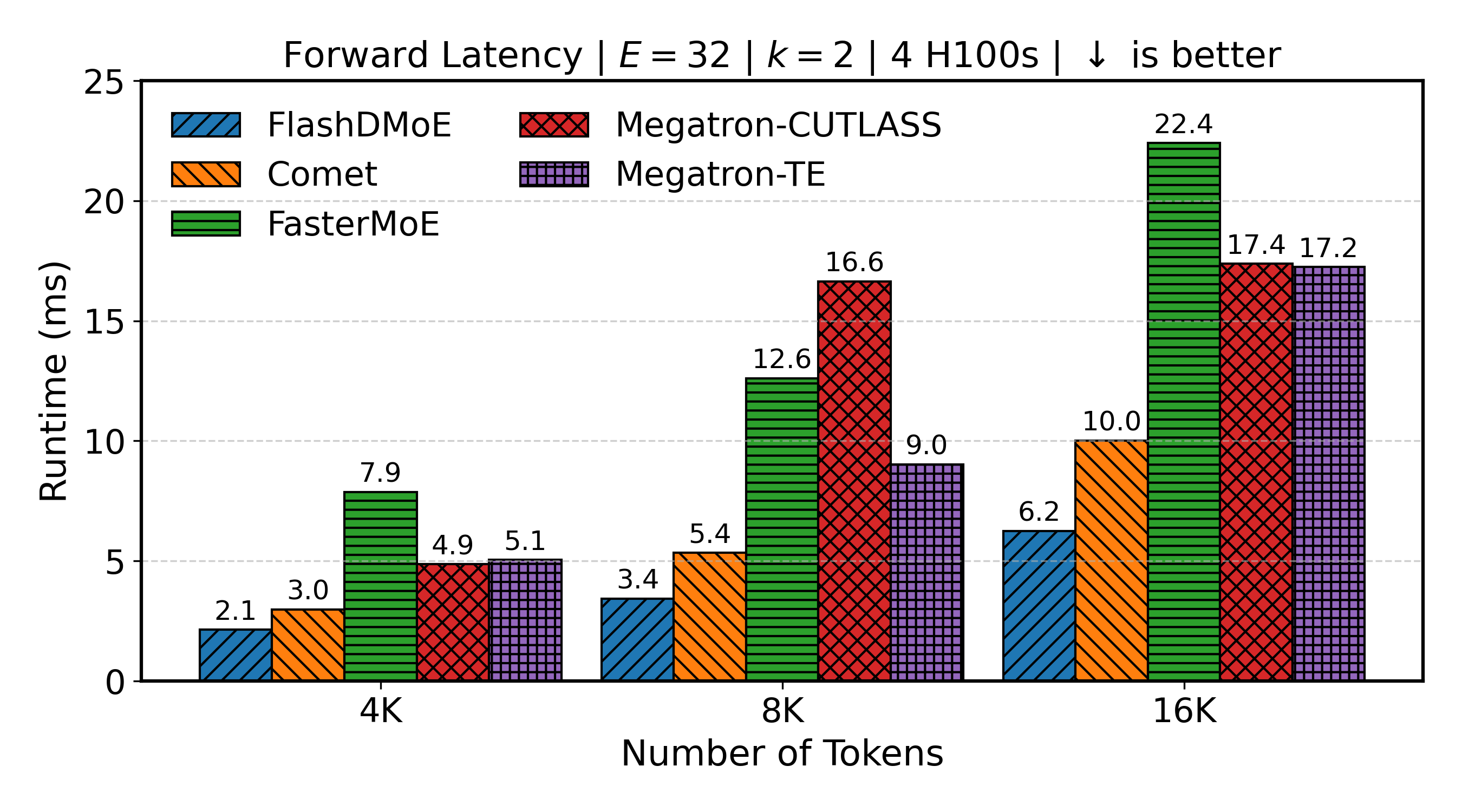
Scaling Tokens (4 GPUs)
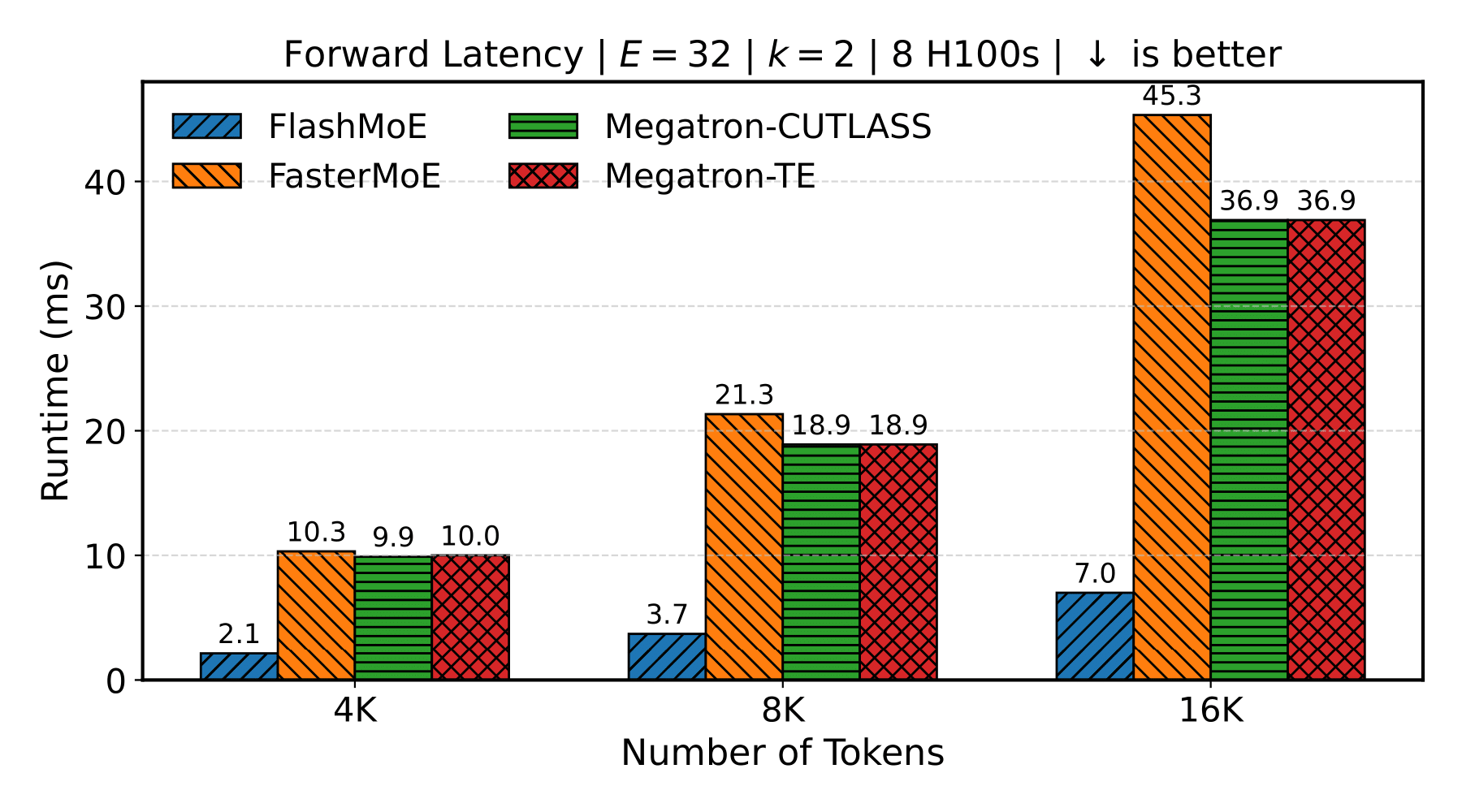
Scaling Tokens (8 GPUs)
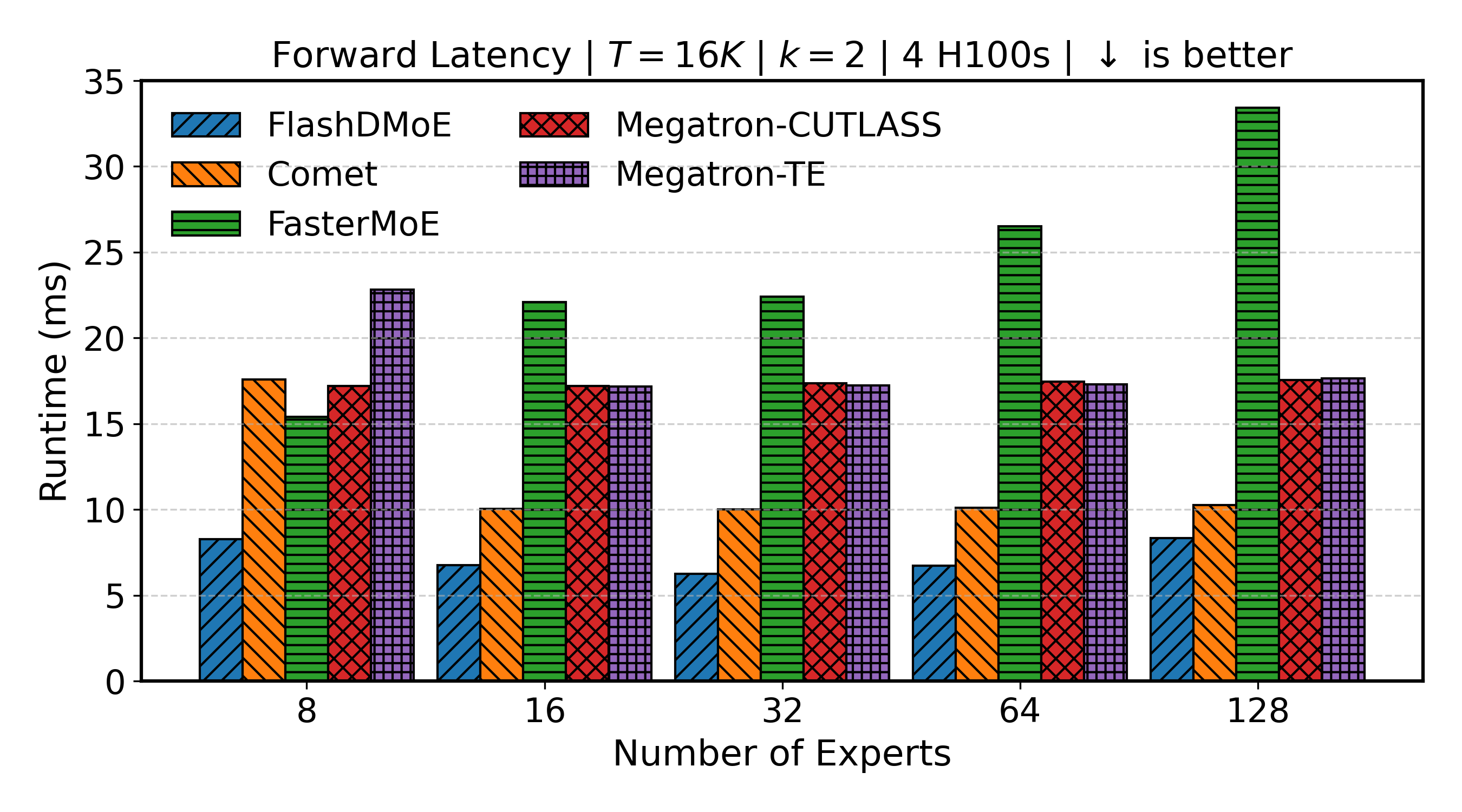
Scaling Experts (4 GPUs)
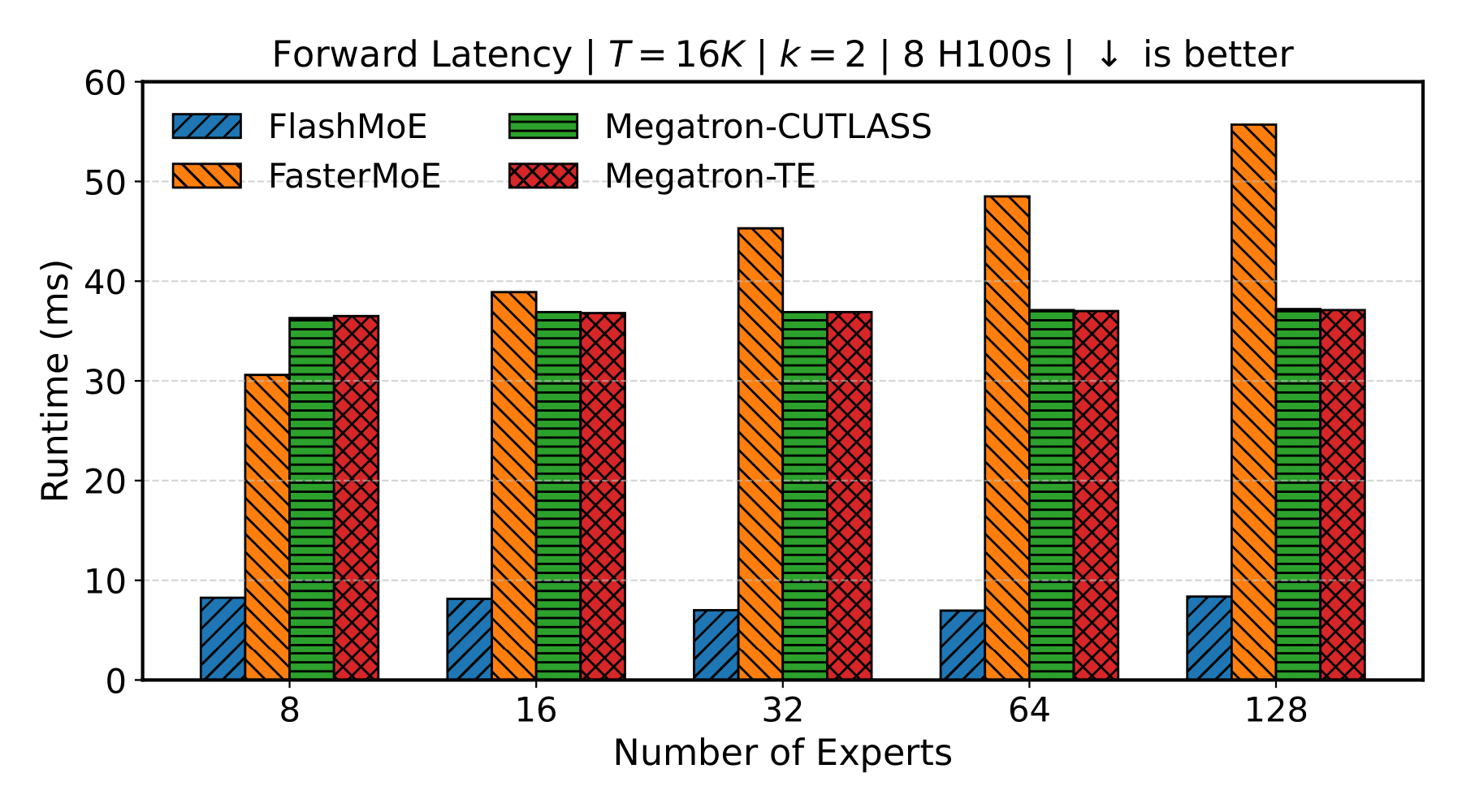
Scaling Experts (8 GPUs)
BibTeX
@article{aimuyo2025FlashMoE,
title={FlashMoE: Fast Distributed MoE in a Single Kernel},
author={Aimuyo, Osayamen Jonathan and Oh, Byungsoo and Singh, Rachee},
journal={Advances in Neural Information Processing Systems},
year={2025},
url={https://neurips.cc/virtual/2025/poster/119124}
}